What is ACAV100M?
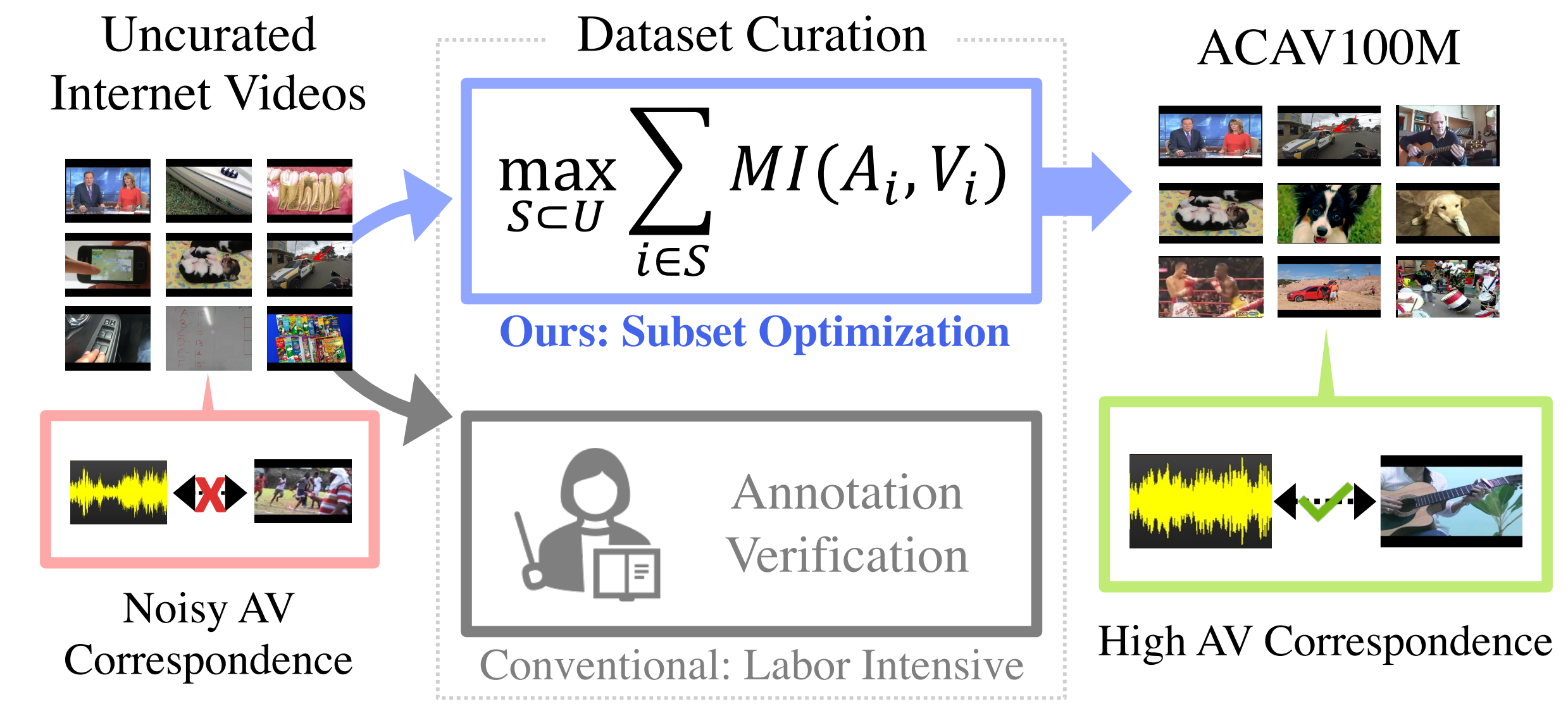
We present an automated curation pipeline for audio-visual representation learning. We formulate an optimization problem where the goal is to find a subset that maximizes the mutual information between audio and visual channels of videos. This helps us find a subset with high audio-visual correspondence, which could be useful for self-supervised audio-visual representation learning.
Using our approach, we created datasets at varying scales from a large collection of unlabeled videos an unprecedented scale: We process 140 million full-length videos (total duration 1,030 years) and produce a dataset of 100 million 10-second clips (31 years) with high audio-visual correspondence. This is two orders of magnitude larger than the current largest video dataset used in the audio-visual learning literature, i.e., AudioSet (8 months), and twice as large as the largest video dataset in the literature, i.e., HowTo100M (15 years).
